Contenido duplicado
¿Qué es el contenido duplicado?
El contenido duplicado se refiere a cuando varias páginas tienen contenido idéntico disponible en diferentes URLs en tu sitio.
Esto es un gran error de SEO.
¿Cómo afecta el contenido duplicado a los rankings?
Las páginas duplicadas perjudican el ranking de tu sitio por muchas razones:
- Los motores de búsqueda son sensibles a la originalidad del contenido alojado en los recursos web. Si hay múltiples páginas con contenido duplicado, es probable que dichas páginas sean penalizadas por Google y afecten negativamente el ranking general de tu sitio en los SERPs.
- La presencia de un gran número de páginas duplicadas complica drásticamente el proceso de indexación del sitio, ya que los motores de búsqueda tienen que gastar su presupuesto de rastreo rastreando las páginas duplicadas, en lugar de tus páginas de alto ranking.
- Hace que sea más difícil clasificar exitosamente las páginas de destino ya que el motor de búsqueda no puede seleccionar objetivamente una página relevante para clasificar, ya que hay múltiples instancias de la misma página.
- El "PageRank" y el "peso" de las páginas se diluyen, ya que los enlaces internos se distribuyen entre las páginas duplicadas.
- Los competidores inescrupulosos también pueden encontrar páginas duplicadas en tu sitio y agregar enlaces externos a ellas. Esto las añadirá al índice del motor de búsqueda y, como resultado, los motores de búsqueda bajarán tu sitio web en los resultados de búsqueda, ya que probablemente serás penalizado por contenido duplicado.
- Google escribe en detalle sobre el impacto negativo de las páginas duplicadas y cómo lidiar mejor con ellas en su artículo titulado "Consolidar URLs Duplicadas."
Las causas más comunes de páginas duplicadas son:
1.- No tener una redirección 301 para las páginas con www y sin www. En este caso, cada página del sitio es un duplicado ya que está disponible en dos direcciones.
Por ejemplo:
- http://example.com/page
- http://example.com/page
2.- Las páginas del sitio están disponibles en la dirección con y sin una barra inclinada. Si no se establece una redirección 301, entonces el software del sitio percibe las siguientes páginas como diferentes aunque el contenido sea idéntico:
Por ejemplo:
- esta URL parece una carpeta en el sitio - termina con '/.'
- http://example.com/page/
- y esta URL es como una página - los nombres de las páginas pueden no terminar con ".php", ".html", etc.
- http://example.com/page
3.- También, las páginas pueden tener .php añadido al final de la URL. Esto causa páginas duplicadas:
Por ejemplo:
- http://example.com/page1
- http://example.com/page1.php
4.- Páginas de grupos de productos con diferentes tipos de opciones de filtrado añadidas a la URL.
Por ejemplo:
- http://example.com/catalog
- http://example.com/catalog?sort=date
- http://example.com/catalog?sort=name
5.- El mismo producto puede estar presente en diferentes tamaños y/o configuraciones de productos. El contenido será el mismo en estas páginas aunque habrá múltiples URLs.
Por ejemplo:
- http://example.com/catalog/shirt155
- http://example.com/catalog/shirt155?color=Orange
6.- Paginación de las páginas de categoría de comercio electrónico. La URL con el número de la primera página añadida se procesa de la misma manera que si el sistema no pasara el parámetro con el número en absoluto. Así, resulta que la misma página tiene diferentes URLs.
Por ejemplo:
- http://example.com/catalog
- http://example.com/catalog?page=1
7.- Puede que hayas configurado el CMS para ignorar y seguir sirviendo páginas con parámetros adicionales añadidos. Esto no se recomienda. Si el sitio no muestra un error 404 cuando añades parámetros inexistentes a una página, entonces dichas páginas pueden ser indexadas y son duplicadas.
Por ejemplo:
- URL normal
- http://example.com/blog
- Parámetro aleatorio añadido a la URL
- http://example.com/blog?blablabla=7777
¿Cómo encontrar páginas duplicadas en tu sitio web?
Puedes encontrar páginas duplicadas en tu sitio en la sección "Auditoría SEO" -> "Páginas duplicadas en tu sitio" del panel de control de Labrika.
Informe de Labrika sobre "Páginas duplicadas en tu sitio":
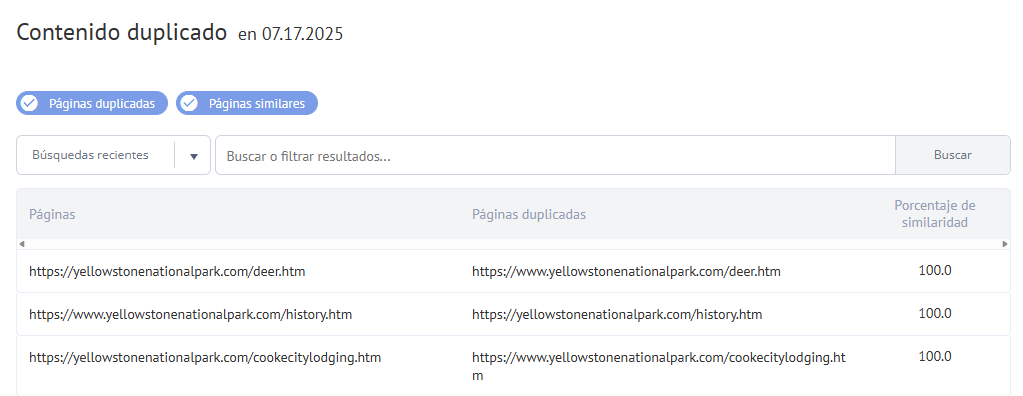
- La URL de la página que tiene un duplicado.
- Lista de duplicados de esta página.
- Porcentaje de similitud de la página.
¿Cómo eliminar páginas duplicadas de tu sitio web?
Maneras de deshacerse de los duplicados:
1.- Puedes eliminar algunos errores de páginas duplicadas simplemente eliminando parámetros innecesarios permitidos en el editor del sitio. En el ejemplo a continuación, puedes ver claramente un enlace que necesita ser limpiado y la segunda opción usada en su lugar:
http://example.com/catalog/shirt155?size=XL
Opción preferida:
http://example.com/catalog/shirt155
2.- Si hay solo un pequeño número de páginas duplicadas encontradas en nuestro informe, entonces puedes simplemente desautorizar ciertas URLs duplicadas para que no sean indexadas. Por ejemplo, probablemente bloquearías a los rastreadores de acceder a la carpeta del catálogo que es parte de la URL de la primera página a continuación, para que solo la segunda URL sea indexada por Google:
- http://example.com/category/product
- http://example.com/product
Añadirías la siguiente línea de código para bloquear la primera página de la indexación en tu archivo robots.txt:
# bloquear la indexación de páginas duplicadas ubicadas en la carpeta '/category':
Disallow: /category
3.- Si las páginas duplicadas parecen ser un problema sistémico para todo tu sitio, entonces el atributo rel=canonical es la mejor solución.
rel=canonical es una etiqueta aplicada a las páginas que esencialmente dice; "Soy la copia maestra de esta página" a los rastreadores de motores de búsqueda cuando rastrean tu sitio.
Una página canónica es una página que recomiendas para la indexación en los motores de búsqueda y lleva el peso de ser 'la' página autorizada para el texto específico de esa página en tu sitio.
Debes establecer la página más autorizada en la lista de páginas duplicadas como la página canónica, y eso instruirá a los motores de búsqueda a ignorar todos los duplicados de la canónica.
El atributo se escribe de la siguiente manera:
# la línea debe colocarse en el bloque <head> en la propia página
<link rel="canonical" href="https://site.com/catalog/shirt" />
Páginas similares
Dentro de tu informe de páginas duplicadas también verás una sección de "páginas similares."
Las páginas similares son páginas que difieren solo por unas pocas palabras en comparación con otras páginas en tu sitio.
Por ejemplo, si tomaste el contenido de una página, cambiaste solo el color del producto, o el nombre de la ciudad, y luego lo guardaste bajo una URL diferente, probablemente aparecería en este informe de páginas similares.
Tales páginas también probablemente desencadenarán penalizaciones por contenido duplicado y también deben ser abordadas siguiendo las mismas prácticas y métodos enumerados en la sección "¿Cómo eliminar páginas duplicadas de tu sitio web?" anterior.
Cómo solucionar el problema
El contenido duplicado dentro de tu sitio es cuando múltiples páginas tienen contenido idéntico.
Estas páginas arruinan los esfuerzos de optimización de tu sitio ya que los motores de búsqueda son sensibles al contenido duplicado, también agrega al presupuesto de rastreo innecesariamente, diluye el page rank y te pone en competencia contigo mismo ya que los motores de búsqueda no saben qué página elegir.
Para solucionar esto, puedes:
- Eliminar parámetros innecesarios que crean URLs adicionales que llevan a la misma página.
- Si no hay muchas páginas con el problema, puedes simplemente desautorizar que se indexen las URLs duplicadas o ciertas secciones de categoría.
- Usar el atributo rel=canonical para especificar la 'página maestra' de todas las páginas duplicadas. Al hacer esto, establece la página más autorizada como la canónica.