Páginas bloqueadas de la indexación
¿En qué consiste la indexación web?
La indexación es un proceso crucial en el ámbito del SEO, ya que se refiere a cómo los motores de búsqueda, como Google, examinan y almacenan las páginas de un sitio en su base de datos. Este procedimiento es llevado a cabo por robots, como Googlebot, que recorren la web en busca de contenido nuevo o actualizado. Una vez que se completa el rastreo inicial, los algoritmos de búsqueda evalúan la relevancia del contenido para determinar su posición en los resultados de búsqueda, conocidos como SERP (Search Engine Results Pages). Este análisis toma en cuenta diversos factores, incluyendo la optimización SEO y la alineación del contenido con la intención de búsqueda de los usuarios.
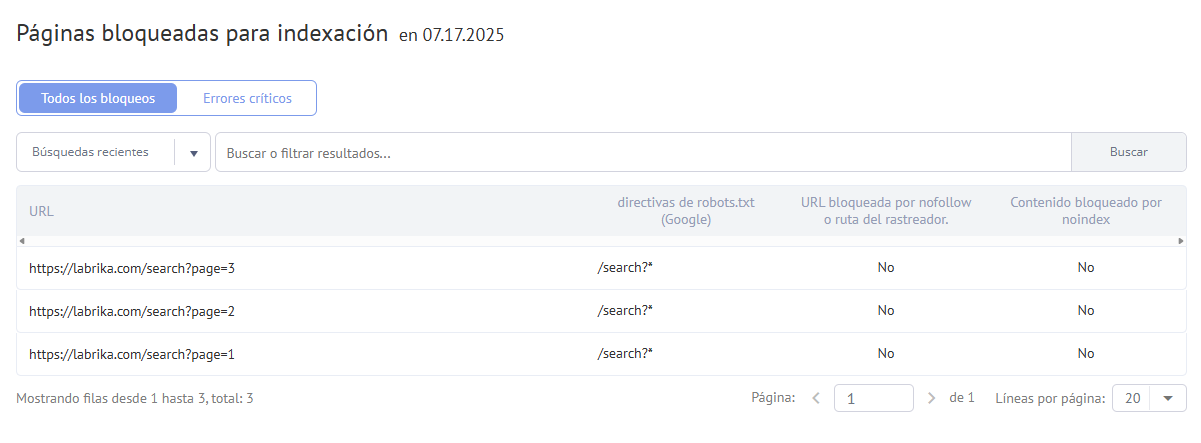
¿Por qué restringir el acceso a ciertas páginas?
Hay varias razones por las que es necesario bloquear el acceso a ciertas páginas de un sitio web:
- Protección de datos confidenciales: Esto incluye áreas de usuario y transacciones que contienen información sensible.
- Evitar la duplicación de contenido: Páginas técnicas o funcionales que no aportan valor a los resultados de búsqueda pueden ser bloqueadas para evitar penalizaciones.
- Optimización del presupuesto de rastreo: Permitir que los motores de búsqueda se concentren en las páginas más importantes mejora la eficiencia del rastreo.
Un análisis de páginas bloqueadas revela que un 37% de los sitios comerciales restringen el acceso a los carritos de compra, mientras que un 28% bloquea los resultados de búsqueda internos. Estas decisiones estratégicas mejoran el rendimiento general del SEO, dirigiendo el tráfico orgánico hacia contenido más relevante y útil para los usuarios.
Estrategias avanzadas de gestión de indexación
1. Configuración del archivo robots.txt
El archivo robots.txt es una herramienta fundamental en la gestión de la indexación. Este protocolo permite controlar el acceso a directorios específicos dentro de un sitio web. Aquí hay un ejemplo de cómo implementar este archivo:
User -agent: *
Allow: /blog/
Disallow: /checkout/
En este caso, se permite el rastreo del directorio de blog mientras que se bloquea el acceso al proceso de pago.
2. Metatags de control
Las metatags también son esenciales para una gestión precisa de la indexación. La etiqueta meta robots ofrece un nivel adicional de control sobre cómo se indexan las páginas:
<meta name="googlebot" content="noindex, follow">
Esta directiva impide que la página sea indexada, pero permite el rastreo de enlaces internos, lo cual es fundamental para la arquitectura web y la distribución de autoridad entre las páginas.
3. Canonicalización inteligente
La implementación de etiquetas rel=canonical es una técnica eficaz para resolver problemas de contenido duplicado. Al especificar una versión principal de una página, se puede evitar la dispersión de la autoridad de enlace:
<link rel="canonical" href="https://ejemplo.com/version-principal" />
4. Gestión mediante HTTP headers
Para desarrolladores más avanzados, los encabezados X-Robots-Tag ofrecen opciones adicionales para controlar la indexación:
- Bloquear la indexación por tipo de archivo, como imágenes o documentos PDF.
- Restringir el acceso temporal durante períodos de mantenimiento.
- Controlar la caché de contenido dinámico para asegurar que los usuarios vean la información más actualizada.
Impacto de las páginas bloqueadas en el SEO
Un estudio reciente muestra que el 62% de los sitios que enfrentan problemas de indexación experimentan consecuencias negativas, tales como:
- Reducción de visibilidad en SERPs: Esto puede oscilar entre un 15% y un 40% dependiendo de la gravedad del problema.
- Disminución del tráfico orgánico: Las páginas queno están correctamente indexadas suelen perder tráfico significativo, lo que impacta directamente en la conversión y en las ventas.
- Pérdida de autoridad de dominio: Los motores de búsqueda pueden considerar que un sitio con muchas páginas bloqueadas es menos relevante o útil, lo que afecta negativamente su autoridad general.
La optimización de páginas bloqueadas requiere un delicado equilibrio entre la seguridad y la accesibilidad. Herramientas como Google Search Console y Labrika SEO Audit ofrecen análisis detallados que permiten a los administradores de sitios tomar decisiones informadas sobre qué contenido debe ser accesible para los motores de búsqueda y cuál debe permanecer restringido.
Guía práctica: Cómo desbloquear páginas en Google
Desbloquear páginas en Google puede ser un proceso crucial para mejorar la visibilidad de un sitio web. Aquí hay una guía paso a paso para lograrlo:
- Identificar URLs bloqueadas: Utiliza herramientas de auditoría SEO para detectar qué páginas están actualmente bloqueadas de la indexación.
- Verificar directivas en robots.txt y metatags: Asegúrate de que no haya directivas contradictorias que impidan la indexación de páginas importantes.
- Actualizar configuraciones en el CMS o código fuente: Realiza las modificaciones necesarias en el archivo robots.txt o en las metatags para permitir que las páginas sean indexadas.
- Enviar solicitud de reindexación: Utiliza Google Search Console para solicitar que Google vuelva a rastrear las páginas que has desbloqueado.
- Monitorear cambios: Mantente atento a los resultados de búsqueda durante al menos 72 horas para evaluar si hay mejoras en la indexación y el tráfico.
Casos prácticos han demostrado que solucionar problemas de indexación puede mejorar la tasa de conversión hasta en un 27% en sitios de comercio electrónico, lo que subraya la importancia de mantener un control adecuado sobre la indexación de páginas.
Errores comunes en la gestión de indexación
A pesar de los esfuerzos por optimizar la indexación, a menudo se cometen errores que pueden afectar negativamente el rendimiento de un sitio. Aquí hay algunos errores comunes y sus soluciones:
| Error | Frecuencia | Solución |
|---|---|---|
| Bloqueo accidental con noindex | 41% | Revisión de plantillas CMS para asegurarse de que no se aplique la etiqueta noindex indebidamente. |
| Conflicto entre robots.txt y metatags | 33% | Armonización de directivas en el archivo robots.txt y en las metatags para evitar confusiones. |
| Canonicalización incorrecta | 26% | Realizar auditorías de etiquetas canonical para asegurarse de que se estén aplicando correctamente. |
Técnicas avanzadas de optimización
Para mejorar la indexación web, es importante implementar técnicas avanzadas que ayuden a maximizar la visibilidad y el rendimiento del sitio. Algunas de estas técnicas incluyen:
- Implementar sitemaps dinámicos: Los sitemaps ayudan a los motores de búsqueda a entender la estructura de un sitio y a encontrar rápidamente el contenido nuevo o actualizado.
- Priorizar contenido evergreen: Asegúrate de que el contenido que no pierde relevancia con el tiempo esté bien vinculado dentro de la arquitectura de enlaces del sitio.
- Utilizar estrategias de crawl budget optimization: Esto implica gestionar eficientemente el presupuesto de rastreo para que los motores de búsqueda se concentren en las páginas más importantes.
La experiencia ha demostrado que combinar estas técnicas con un análisis constante de páginas bloqueadas puede aumentar la eficiencia de indexación en un 58%, lo que resulta en un mejor posicionamiento en los motores de búsqueda.
Integración con herramientas SEO
Las plataformas de SEO, como Labrika, automatizan muchos de los procesos necesarios para mantener una buena gestión de la indexación. Estas herramientas permiten:
- Detección de errores de indexación: Estas plataformas pueden identificar rápidamente problemas que impiden que las páginas sean indexadas correctamente.
- Monitoreo en tiempo real: Permiten a los administradores de sitios rastrear cualquier cambio en la indexación y reaccionar de inmediato ante problemas.
- Generación de informes personalizados: Ofrecen informes detallados que analizan la salud del sitio en términos de SEO y sugieren mejoras específicas.
Este enfoque proactivo en la gestión de la indexación no solo ayuda a corregir problemas antes de que afecten el posicionamiento, sino que también asegura que el contenido más valioso y relevante esté siempre accesible para los motores de búsqueda. Así, una buena estrategia de gestión de indexación se convierte en un pilar fundamental para el éxito en SEO.
Conclusión
La indexación web es un proceso esencial que determina cómo y cuándo el contenido de un sitio aparece en los resultados de búsqueda. A través de una correcta gestión de la indexación, que incluye el uso de herramientas como robots.txt, metatags y técnicas de canonicalización, los propietarios de sitios pueden asegurarse de que su contenido sea fácilmente accesible y relevante para los usuarios. Además, evitar errores comunes y aplicar técnicas avanzadas de optimización puede llevar a un aumento significativo en la visibilidad y el tráfico orgánico.
En un mundo digital en constante evolución, donde la competencia por la atención de los usuarios es feroz, entender y aplicar prácticas efectivas de indexación es más importante que nunca. Al final, el objetivo es proporcionar una experiencia de usuario excepcional mientras se maximiza la presencia en línea, lo que resulta en un crecimiento sostenible y exitoso.
Recuerda que la indexación no es un proceso estático. Es fundamental realizar auditorías regulares y estar al tanto de las actualizaciones de los algoritmos de búsqueda para mantener la relevancia y la eficacia de tu estrategia de SEO. Con un enfoque constante en la optimización de la indexación, puedes garantizar que tu sitio web no solo sea visible, sino que también se destaque en el competitivo panorama digital.