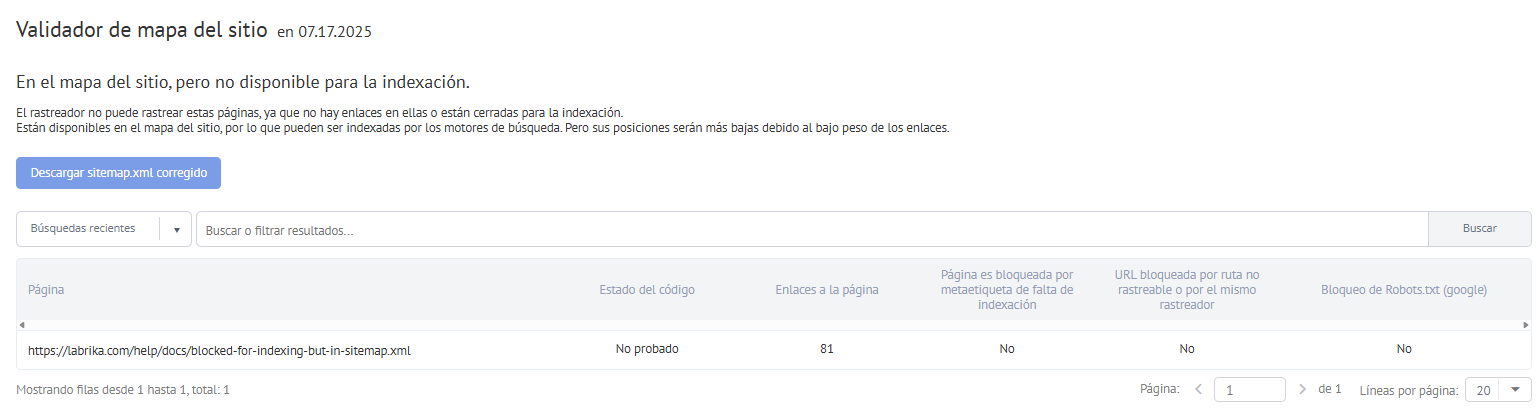
En el sitemap pero no disponible para indexación
Un archivo Sitemap.xml es esencialmente un mapa de su sitio web diseñado específicamente para facilitar la navegación y la indexación de su sitio por parte de los motores de búsqueda. Se encuentra dentro de su carpeta public_html (o raíz del sitio) e incluye instrucciones importantes para los rastreadores de motores de búsqueda que especifican qué páginas deben ser visitadas, en qué orden y con qué frecuencia deben visitarlas.
Esto acelera drásticamente el proceso de indexación de las páginas importantes y permite que los rastreadores de búsqueda asignen su tiempo de rastreo a páginas de alta importancia tanto para usted como para sus usuarios.
Crear un sitemap.xml no siempre es necesario, pero siempre es recomendable, especialmente para sitios grandes con miles de páginas. Con sitios más grandes, surge la necesidad de asegurarse de que los rastreadores de motores de búsqueda dediquen su tiempo a esas páginas de alto valor con contenido profundo e intención comercial, no a páginas secundarias que ofrecen poco valor.
Como regla general, cuando el software y los CMS generan automáticamente un archivo sitemap.xml, incluyen todas las páginas disponibles para indexación. Es probable que un propietario típico de un sitio web no sea consciente de esto, y aunque haya configurado noindex para ciertas páginas, sus sitemaps generados automáticamente probablemente incluyan estas páginas y desperdicien valiosos presupuestos de rastreo.
Se recomienda encarecidamente usar plugins, software personalizado o generadores de sitemaps para configurar URL específicas que se mostrarán en su sitemap, ciertas URL que deben evitarse, el orden en que se deben rastrear las URL y con qué frecuencia deben rastrearse.
Errores de sitemap encontrados por Labrika
¡Atención! El informe de errores del sitemap solo será accesible si se configuran correctamente los permisos suficientes para escanear todo el sitio web. De lo contrario, Labrika solo podrá ver las páginas específicamente listadas en el archivo sitemap.xml en lugar de poder ver todas las páginas del sitio web y luego compararlas con las páginas listadas en el sitemap.
El análisis de sitemap de Labrika ayuda a encontrar los siguientes tipos de errores:
- Páginas que existen en el sitemap pero no son accesibles para la indexación.
- Páginas que existen en el sitemap pero tienen una etiqueta noindex.
- Páginas que no existen en el sitemap pero son indexables.
Tenga en cuenta: los diferentes motores de búsqueda procesan las reglas del sitemap de diferentes maneras. Google, con mayor frecuencia, solo indexará páginas que se pueden alcanzar a través del rastreo automático sin un sitemap. Es decir, páginas que se pueden alcanzar a través de enlaces internos dentro del tiempo de rastreo y la profundidad de rastreo asignados para su sitio ese día. No mirarán su archivo sitemap.xml para determinar qué enlaces rastrear, sino que usarán el sitemap como una guía para saber con qué frecuencia rastrear las páginas listadas en el sitemap.
La página existe en el sitemap, pero no es accesible para la indexación
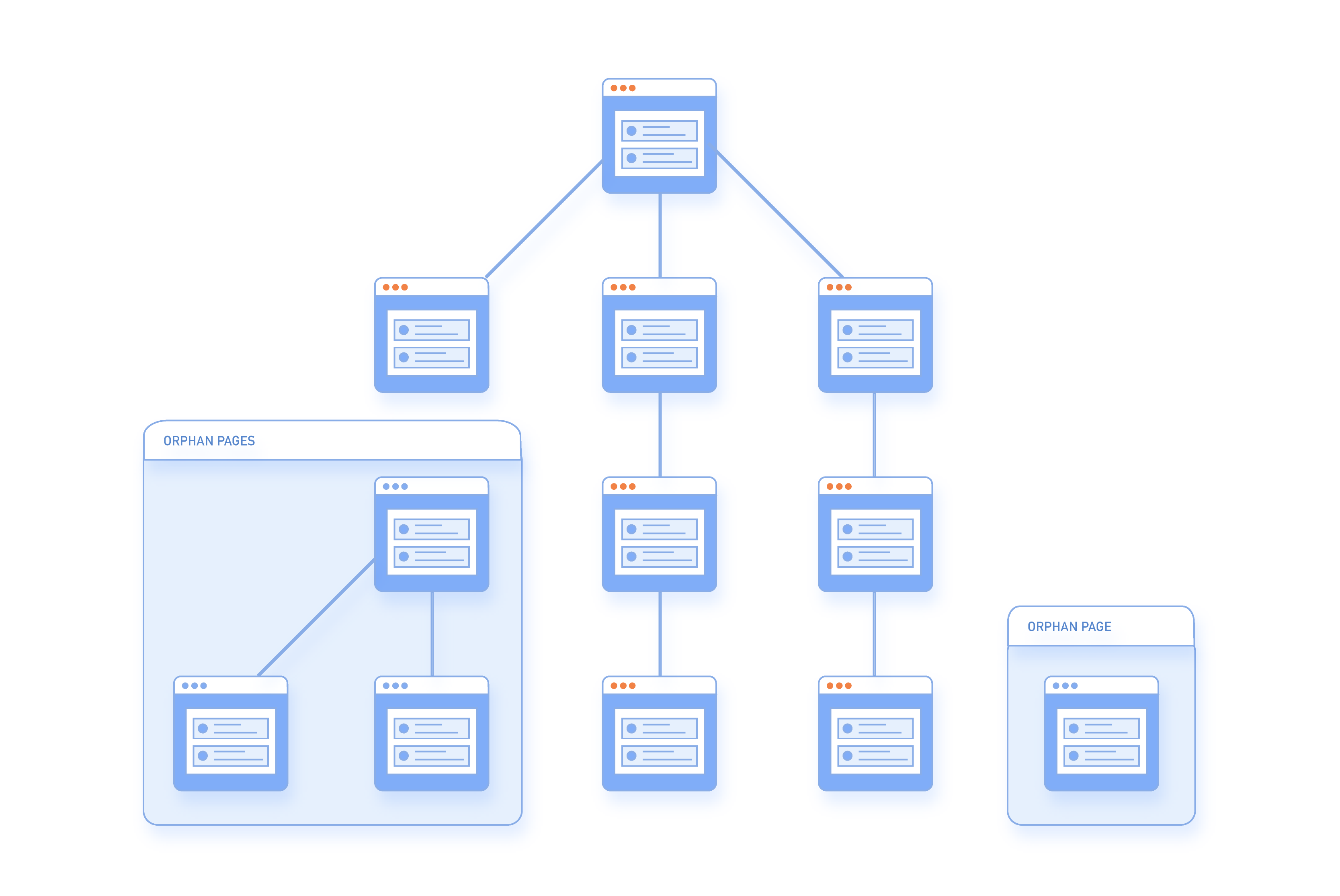
Este informe destaca principalmente las páginas huérfanas, que son esencialmente páginas que existen en su sitio pero no tienen enlaces entrantes que apunten a ellas y están ‘sin dueño’.
En el caso de que tales páginas de algún modo sean indexadas por los motores de búsqueda, es probable que tengan un PageRank cero y no se clasifiquen bien. Está bien documentado en línea que Google y otros grandes motores de búsqueda utilizan puntajes de PageRank (y sus diversas formas) para determinar el poder SEO y el valor de las páginas. Hace solo unos años, Google permitía utilizar una barra de herramientas que mostraba el PageRank de sus páginas, pero desafortunadamente, eso fue retirado del ámbito público. Naturalmente, desea un buen PageRank para sus diferentes páginas, por lo que si una de sus páginas de destino termina apareciendo en esta categoría de error (es decir, su página no es solo una página huérfana), entonces querrá llegar a la raíz del problema de inmediato.
Razones comunes por las que su página existe en el sitemap, pero no es accesible para la indexación:
- Un enlace desde una página con etiqueta noindex conduce a esta página, o las páginas que conducen a esta página no son responsivas. Como resultado, el rastreador de motores de búsqueda no puede avanzar ni retroceder y, por lo tanto, termina la sesión.
- Los enlaces a las páginas necesarias están bloqueados. Por ejemplo, a través del atributo rel="nofollow". Es decir, el rastreador ve el enlace a la página, pero no puede navegar a ella porque está prohibido.
- No hay enlaces a esta página y está verdaderamente ‘huérfana’.
- La página fue eliminada en el editor del sitio web/CMS, pero el archivo HTML aún permanece activo en el sitio.
- La página existe en el sitemap pero no es rastreable, por lo que no puede ser indexada.
Este tipo de error se corrige mejor haciendo lo siguiente:
Verifique qué páginas tienen etiquetas noindex y nofollow y rectifique y/o asegúrese de que la página se haya agregado correctamente al menú principal para permitir un rastreo correcto. Además, más a menudo que no, vemos este tipo de error en sitios comerciales e informativos que bloquean la paginación.
¿Cómo solucionar el problema?
Cuando una página está disponible en el sitemap pero no tiene enlaces internos desde ninguna otra página del sitio, se conoce como una página huérfana.
Las páginas huérfanas son malas para el SEO ya que no tienen peso de enlace y, por lo tanto, son consideradas sin importancia por los motores de búsqueda. También se usaban anteriormente en SEO de sombrero negro.
Una vez identificadas en nuestro panel de control, puede:
- Reintegrar la página en el esquema de enlaces de su sitio si la página es útil, se clasifica para palabras clave o tiene backlinks de sitios externos.
- Fusionar la página con otra si tiene una página casi duplicada ya enlazada en el sitio.
- Eliminar la página por completo si no tiene uso. O devolver un código 404, o 410 (contenido expirado).
- Para páginas de productos donde el artículo puede haber expirado, puede enlazar a nuevos productos en la misma categoría, haciendo de la página una nueva fuente de leads. (Esto es lo que hace eBay con las listas de subastas expiradas). Ayudando a generar más tráfico.
La página existe en el sitemap pero tiene una etiqueta noindex
Estas son páginas que han sido prohibidas de la indexación mediante una etiqueta noindex, pero aún existen en algún lugar del sitemap.
Las personas etiquetan páginas como noindex por una variedad de razones, pero tener páginas noindex listadas en el sitemap puede llevar a la filtración de datos confidenciales, pero lo más probable es que resulte en que los rastreadores desperdicien su tiempo y presupuesto de rastreo.
Para solucionar este problema, simplemente necesita eliminar la página/páginas noindex del sitemap para evitar que cualquier motor de búsqueda indexe inadvertidamente una página que no debería (aunque normalmente siguen la etiqueta noindex).
¿Cómo solucionar el problema?
Esto ocurre típicamente cuando una página ha sido bloqueada de la indexación a través de un atributo rel="nofollow".
Incluir estas páginas en el sitemap no es útil ya que usa el presupuesto de rastreo y podría potencialmente llevar a la filtración de información confidencial. Para solucionar esto, simplemente puede eliminar la página de su sitemap.
Descargue el archivo Sitemap.xml sin errores de Labrika
Para cada uno de los diferentes informes de errores de sitemap listados anteriormente, Labrika le ofrece la posibilidad de descargar una versión corregida y sin errores de su archivo sitemap.xml. Esto debería ahorrarle tiempo al corregir manualmente su propio archivo sitemap.xml y, lo más importante, hacer un mejor uso de sus presupuestos de rastreo de motores de búsqueda.